使用新安装的 myeclipse 打开了曾经的项目,发现原来的中文注释,全部变成乱码了。于是头皮一阵发麻,对于喜欢透明的程序员来说,看不懂又想要弄明白的乱码十分揪心。
网上搜索了一阵,发现原因是新安装的 myeclipse 默认使用 cp1252 编码,只要将其改成支持中文字符的 UTF-8 即可解决中文乱码问题。
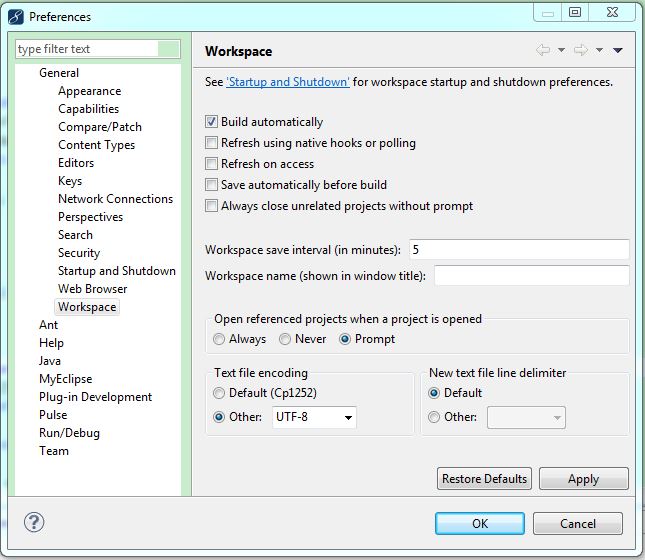
- Preferences -> General -> Workspace -> Text file encoding
- 将 Text file encoding 改为 UTF-8
为了彻底弄明白字符乱码的原因,下功夫学习了一番,将学习和思考的内容写在这篇博客中。
字符编码举例
我们在计算机屏幕上看到的是实体化的文字和符号,而在计算机存储介质中存放的实际是二进制的比特流。把实体化的文字转换成二进制比特流的过程,就是“编码”,将比特流转化成文字的过程,就是“解码”。
比如,“永”字在不同字符编码表的十六进制和二进制编码结果如下:
| 字符编码表 | 十六进制编码 | 二进制编码 |
|---|---|---|
| UTF-8 | E6B0B8C281 | 1110 0110 1011 0000 1011 1000 1100 0010 1000 0001 |
| UTF-16 | 6C380081 | 0110 1100 0011 1000 0000 0000 1000 0001 |
| GBK | D3C03F | 1101 0011 1100 0000 0011 1111 |
由此可见,如果在编码和解码是采用了不同的字符编码表,那么就会产生错误的解码结果,有时甚至无法看到结果。
在文章开头的例子中,就是使用了 UTF-8 的编码方式,又采用 Cp1252 来解码,导致了乱码的结果。
字符编码的概念
首先明确一些字符编码的术语:
- 字符库(Character Repertoire):字符库是字符抽象列表,具有超过一百万中字符,包括拉丁字母、西里尔字母、中文、韩文、日文、希伯来文、亚拉姆语等等,还包括其他一些特殊符号。
- 编码字符集(Coded Character Set, CCS):编码字符集是字符集和数字的映射。一个字符与一个数字唯一对应。
- 字符编码表(Character Encoding Form, CEF):字符编码表是庞大的编码字符集与较小的实际存储的数值的转换关系。
- 编码值(Code Point):编码值就是唯一标识字符的数字。
- 编码单位(Code Unit):对于一个编码值,可以由多个编码单位组成。这是由特定的字符编码表决定的。
Unicode 和 UTF-8
Unicode 对世界上大部分的文字系统进行了整理和编码,使得电脑可以用更为简单的方式来呈现和处理文字。Unicode 使用使用16位的编码空间,也就是每个字符占用2个字节。这样理论上一共最多可以表示2^16(即65536)个字符。
![]()
Unicode 的实现方式不同于编码方式。一个字符的 Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定相同,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。Unicode 的实现方式称为 Unicode 转换格式(Unicode Transformation Format,简称为 UTF)
例如,如果一个仅包含基本7位 ASCII 字符的 Unicode 文件,如果每个字符都使用2字节的原 Unicode 编码传输,其第一字节的8位始终为0。这就造成了比较大的浪费。 所以,Unicode 就是上文提到的 CCS,诸如 UTF-8 就是一种 CEF。
下面讲解 UTF-8 的编码实现方式,可以更好地理解字符编码表,理解 UTF-8 与 Unicode 的转换关系。
UTF-8 编码方式
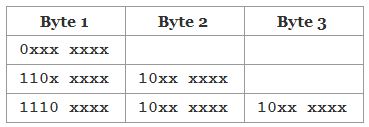
UTF-8 (8-bit Unicode Transformation Format) 编码为变长编码。编码单位(Code Unit)为一个字节。一个字节的前1-3个bit为描述性部分,后面为实际序号部分。
- 如果一个字节的第一位为
0,那么代表当前字符为单字节字符,占用一个字节的空间。0之后的所有部分(7个bit)代表在 Unicode 中的序号。 - 如果一个字节以
110开头,那么代表当前字符为双字节字符,占用2个字节的空间。110之后的所有部分(5个bit)加上后一个字节的除10外的部分(6个bit)代表在 Unicode 中的序号。且第二个字节以10开头 - 如果一个字节以
1110开头,那么代表当前字符为三字节字符,占用2个字节的空间。1110之后的所有部分(4个bit)加上后两个字节的除10外的部分(12个bit)代表在 Unicode 中的序号。且第二、第三个字节以10开头 - 如果一个字节以
10开头,那么代表当前字节为多字节字符的第二个字节。10之后的所有部分(6个bit)和之前的部分一同组成在 Unicode 中的序号。
具体每个字节的特征可见下表,其中 x 代表序号部分,把各个字节中的所有 x 部分拼接在一起就组成了在Unicode字库中的序号。
我们分别看三个从一个字节到三个字节的 UTF-8 编码例子:

细心的读者可以得出以下规律:
- 3个字节的 UTF-8 十六进制编码一定是以
E开头的 - 2个字节的 UTF-8 十六进制编码一定是以
C或D开头的 - 1个字节的 UTF-8 十六进制编码一定是以比
8小的数字开头的
还原 myeclipse 乱码的过程,并且修正乱码
以下代码,使用 Navicat for MySQL 环境模拟。
那么,文章最初提到的 myeclipse 打开文件乱码,是怎么产生的呢?以下还原了这个过程。
执行语句:
select hex( convert('这里是注释' using utf8) )
得到结果:
E8BF99E9878CE698AFE6B3A8E9878A
执行语句:
select convert(0xE8BF99E9878CE698AFE6B3A8E9878A using latin1)
latin1 编码就是 MySQL 中的 Cp1252 编码
得到结果:
这里是注释
上一行,就是我们不愿看到但是出现了的乱码!
假设我们得到了上面的乱码结果,然后查看 myeclipse 的默认编码,发现是 Cp1252,接着,我们知道原文件是用 UTF-8 编码的(或者说,猜测是 UTF-8 编码),我们就可以进行乱码的还原。
执行语句:
select hex( convert('这里是注释' using latin1) )
得到结果:
E8BF99E9878CE698AFE6B3A8E9878A
执行语句:
select convert(0xE8BF99E9878CE698AFE6B3A8E9878A using utf8)
得到结果:
这里是注释
到这里,正确的文字信息显示出来了!
注意:有些情况下,使用错误的编码打开文件,然后再次保存的时候,会出现提示,用当前编码保存,将会丢失字符。这是因为新编码无法完全解析旧编码生成的二进制比特流。某些智能的 IDE 可以提示用户使用另外一种编码格式保存当前文件。
小结
本文简单介绍了字符编码的概念,阐述了乱码产生的原因。通过对 UTF-8 编码方式的介绍,了解了一种常用的可变长度的字符编码表。一般情况下,乱码会出现在编程开发的 IDE 和文本处理工具中。只要选择了与文本被保存时相同的编码,就可以看到正确的文字。
另外,如果试图识别乱码,就需要知道显示工具所使用的编码和文件保存时使用的编码。上文提到的 UTF-8 的编码规律,可以用来猜测文本在保存时是否可能使用了 UTF-8 编码。通过解码和再编码的过程,可以尝试识别乱码所要表达的文字。
附录:常用的编码及其含义
- ascii – US ASCII
- big5 – Big5 Traditional Chinese
- gb2312 – GB2312 Simplified Chinese
- gbk – GBK Simplified Chinese
- latin1 – cp1252 West European
- utf8 – UTF-8 Unicode
参考资料
- 十分钟搞清字符集和字符编码 (借鉴了很多)
- Wikipedia上的内容,包括“字符编码”、“Unicode”、“UTF-8”、“ASCII”、“Windows-1252”等。
- 字符编码笔记:ASCII,Unicode和UTF-8 (辅助参考)
This work is licensed under a CC A-S 4.0 International License.